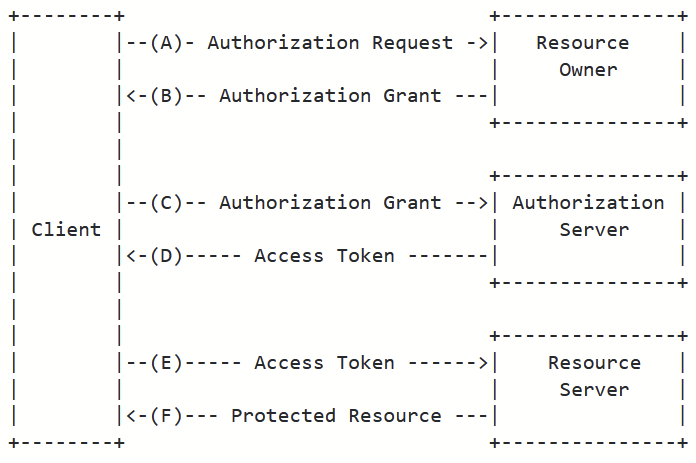
The OAuth2 spec cleanly separates the role of Authorization Server (AS) from that of Resource Server (RS). The role of the AS, and the whole OAUTH2 dance, is to get an access token that will be accepted by a RS.
It’s puzzling. It should be easy, nay, trivial, to implement the Resource Server side in Django, yet it’s not. There are several libraries whose description can be interpreted as “implementing OAuth2”, yet what they all do is implement the Authorization Server side. I want to consume access tokens, not issue them!
Now, in theory the access token could be anything. But common Authorization Server implementations (keycloak, authentik, various hosted services) have converged on issuing signed JSON Web Tokens. So what the resource server needs is to be configured with the key to verify the tokens. We could conceivably hard code the key in source or configuration, but that is a bit of a hassle, and anyway, this is the third decade of the third millennium, quite frankly we shouldn’t have to. All server implementations offer a JWKS endpoint where the currently valid keys can be queried (and even a full autodiscovery endpoint, to discover the JWKS endpoint). An implementation of a resource server should, in theory, only need to be pointed at the JWKS endpoint and everything should just work.
We want to authorize requests. Every time a new request comes in. That’s what a Resource Server does. It uses the provided token to check authorization. And apparently the documentation seems to suggest the correct way to do this is to fetch the keys from the JWKS endpoint on every request.
WTF?
We’ll need some caching. The documentation is mum on the topic. The implementation however is not. Turns out, they have implemented a cache. Only, they have implemented it on the PyJWKClient object itself. And there’s no easy way to hook up a real cache (such as Django’s).
The usual flow for normal Python web frameworks is that no object survives from request to request. Each request gets a clean slate. They may run in the same process sequentially. In different threads in the same process. In multiple processes. Or even async in the same thread in the same process. With the given example code we would be hitting the authorization server JWKS endpoint for every incoming request, adding huge latencies to processing.
In order to retain even a shred of sanity, we have no choice but to turn the JWKClient into a kind of singleton. It looks like this:
import jwt
from django.conf import settings
_jwks_client: Optional[jwt.PyJWKClient] = None
def get_jwks_client() -> jwt.PyJWKClient:
# PyJWKClient caches responses from the JWKS endpoint *inside* the PyJWKClient object
global _jwks_client
if _jwks_client:
return _jwks_client
_jwks_client = jwt.PyJWKClient(settings.JWKS_URI)
return _jwks_client
With this definition in place you can get the signing key as signing_key = get_jwks_client().get_signing_key_from_jwt(token) and will at least get some caching within a process, until the server decides to spawn a new process.
Then, to hook up authentication into Django Rest Framework you’ll do something like this (where User.from_token needs to be something that can turn a verified JWT dict into a User object):
def authenticate_request(request):
if header := get_authorization_header(request):
match header.split():
case b"Bearer", token_bytes:
token = token_bytes.decode("us-ascii", errors="strict")
signing_key = get_jwks_client().get_signing_key_from_jwt(token)
data = jwt.decode(token, signing_key.key, algorithms=["RS256"])
if data:
return User.from_token(data), data
Many, many years ago, this was with Bugzilla in the early 2000s, I got my first automated lecture on what constitutes a good bug report. I probably didn’t pay attention. Since then, I’ve seen this list countless times, in various levels of detail, across a broad array of systems:
What did you do?
What happened?
What did you expect to happen?
Over the last few years I’ve come to realize that this list is irreducible, if you’re losing one item you lose important context, and represents a kind of deep wisdom:
What Did You Do? — If we cannot see the steps that brought you into the situation, it’ll be hard to find the place in the program where it happens. It’ll also set up our mental model of the program in question to see what we think should happen. Preferably this should be detailed and reliable enough to reproduce the problem on our side. Things that cannot be reliably reproduced are very hard to fix, because you’ll never truly know if they’re gone.
What happened? — This gives context on what happened for you, which might be different for us, indicating some other issue. In some cases this is what we thought should happen, so this also gives a clear statement to set up the next point.
What did you expect to happen? — Stating how your expectation differs from reality is what makes this a bug. You’re not reporting issues where the system does what you expected it should do. But this expectation might differ from what we were expecting. The issue need not be in the code or the implementation, but might be somewhere else. Maybe the documentation gave you a wrong idea on what should happen?
Sometimes a bug report can be succinct but still contain all three items: “I clicked on save. It did not save. I expected it to save.” Though in this case the first part really should be longer, because this is probably something that only happens under certain circumstances. And even if part 3 is only “I expected it to work”, that’s good to write out.
Bug reports consisting of a single screenshot, for example of an error message, are often not helpful. They, more or less, cover part 2, but leave out important context. It may not be obvious from the screenshot on how to get there. And it’s as likely as not that we think that this is the expected behavior. You should state why you think this error message is, as it were, in error.
The three parts of a good bug report are interlocking. Like describing the way to the train station to a stranger. You’re not going to describe it as “Turn left second street, go right first street, go right third street.” You’re giving context: “Go down this street and turn left at the second intersection, right behind the flower shop. You should see the church in front of you, turn immediately right and go into the small alley. If you then turn right at the third street you should see the train station in the distance.”
This is redundant. But redundancy is good. It allows for error checking and correction. It allows for there to be errors in both the environment and in its mental model or description thereof.
So, repeat after me: What did you do? What happened? What did you expect to happen?
Given: There’s a CI system that automatically builds docker images from your VCS (e.g. git), we use self-hosted gitlab. Goal: Both initial and subsequent automated deployments to different environments (staging and production).
Rejected Approaches
Most existing blog articles and howtos for this use case, specifically in the context of gitlab, tend to be relatively simple, relatively easy, and very very wrong. The biggest issue is with root access to the production server. I believe that developers (and the CI/CD system) should not have full root access to the production system(s), to retain semblance of separation in case of breaches. Yes, sure, a malicious developer could still check-in bad code which might eventually get deployed to production, but there is (should be) a review process before that, and traces in the VCS.
And yet, most recommendations on how to do deployment with gitlab circle around one of two approaches:
Install a gitlab “runner” on your production server. That is, an agent which gets commands from the gitlab server and executes them. This runner needs full root access (or, equivalently, docker daemon access), thus giving the gitlab server (and anyone who has/gains control over it) full root access to the production system(s). This approach also needs meticulous management of the different runners, since they are now being used not just for build purposes but also have a second, distinct, duty for deployment.
Use your normal gitlab runners that are running somewhere else, but explicitly give them root access to the target servers, e.g. with a remote SSH login. Again, this gives everybody in control of the gitlab server full production access, as well as anybody in control of one of the affected runners. Usually this is made less obvious by “only” giving docker daemon access, but that’s still equivalent to full root access.
There’s variants on this theme, like using Ansible for some abstraction, but it always boils down to somehow making it so that the gitlab server is capable of executing arbitrary commands as root on the production system.
Our Approach
For container management we’re going to use docker compose, the new one, notdocker-compose. A compose.yaml file (with extensions, see below) is going to fully describe the deployment, and compose will take care of container management for updates.
Ideally we want to divide the task into two parts:
Initial setup
Continuous delivery
For the initial setup there’s not a pressing reason for full automation. We’re not setting up new environments all the time. There’s still some best practices and room for automation, see below, but in general it’s a one-time process executed with high privileges.
The continuous updates on the other hand should be fast, automated, and, above all, restricted. An update to a deployed docker application does exactly one thing: pull new image(s) then restart container(s).
Restricted SSH keys for update deployment
Wouldn’t it be great if we had an agent on the production server that could do that, and only that? Turns out, we have! Using additional configuration on ~/.ssh/authorized_keys we can configure a public key authenticated login that will only execute a (set of) predefined command(s), and nothing else1. And since sshd is already running and exposed to the internet anyway, we don’t get any new attack surface.
The options we need are:
restrict to disable, roughly, all other functionality
command="cd ...; docker compose pull && docker compose up -d" which will make any login with that key execute only this command (you’ll need to fill in the path to cd into).
Using docker compose
In order for this to seamlessly work, there’s some best practices to follow when creating the environment:
All container configuration is handled by the docker compose framework
Specifically: docker compose upjust works. No weird docker compose -f compose.foo.yaml -f compose.bar.yaml -e WTF_AM_I_DOING=dunno up incantations.
The docker compose configuration should itself be version controlled
The containers come up by themselves in a usable configuration, and can handle container updates gracefully
For example in Django, the django-admin migrate call must be part of the container startup
In general it’s not allowed to need to manually execute commands in the containers or the compose environment for updates. You’re allowed to require one necessary initialization command on first setup, under extenuating circumstances only.
There’s also good container design (topic of a different blog post) with regards to separation of code and data
Good docker compose setup
There’s two ways to handle the main compose configuration of a project: As part of the git repository of one of the components, or as a separate git repository by itself.
The first approach applies if it’s a very simple project, maybe just one component. If it contains only the code you wrote, and possibly some ancillary containers like the database, then you’ll put the compose.yaml into the root directory of the main git repository. This also applies if your project consists of multiple components maintained by you, but it’s obvious which one is the main one (usually the most complex one). Like if you have a backend container (e.g. Python wsgi), a frontend container (statically compiled HTML/JS, hosted by an nginx), a db container (standard PostgreSQL), maybe a cache, and some helper daemon (another Python project). Three of these are maintained by you, but the main one is the backend, so that’s where the compose.yaml lives.
For complex projects it makes sense to create a dedicated git repository that only hosts the compose file and associated files. This specifically applies if the compose file needs to be accompanied by additional configuration files to be mounted into the containers. These usually do not belong in your application’s git repository.
The idea here is that the main compose.yaml file (using includes is allowed) handles all the basic configuration and setup of the project, independent of the environment. Doing a docker compose up -d should bring up the project in some default state configured for a default environment (e.g. staging). Additional environment specific configuration should be placed in a compose.override.yaml file, which is not checked into git and which contains all the modifications necessary for a specific environment. Usually this will only set environment variables such as URL paths and API keys.
Additional points of note:
All containers should be configured read_only: true, possibly assisted by tmpfs: ["/run","/var/run/someapp"] or similar. If that’s not possible, go yell at the container image creator2.
All configuration that is mounted from the outside should be mounted read-only
Data paths are handled by volumes
The directory name is the compose project name. That’s how you get the ability to deploy more than one instance of a project on the same host. The directory name should be short and to the point (e.g. frobnicator or maybe frobnicator-staging).
Ports in the main compose.yaml file are a problem, since port numbers are a global resource. A useful pattern is to not specify a port binding in the compose.yaml file and instead rely on compose.override.yaml for each deployment to specify a unique port for this deployment. That’s one of the few cases where it’s acceptable to absolutely require a compose.override.yaml for correct operation, and it must be noted in the README.
Putting It All Together
This example shows how to set up deployment for project transmogrify/frobnicator, hosted on gitlab at git.example.com, with the registry accessible as registry.example.com, to host deploy-host, using non-root (but still docker daemon capable) user deploy-user.
Preliminaries
On deploy-host, we’ll create a SSH public/private key to be used as deploy key for the git repository containing the main compose.yaml and configure docker pull access. This probably only needs to be done once for each target host.
ssh-keygen -t ed25519
Just hit enter for default filename (~/.ssh/id_ed25519) and no passphrase. Take the resulting public key (in ~/.ssh/id_ed25519.pub) and configure it in gitlab as a read-only deploy key for the project containing the compose.yaml (under https://git.example.com/transmogrify/frobnicator/-/settings/repository).
We’ll also need a deploy token for docker registry access. This should be scoped to access all necessary projects. In general this means you’ll want to keep all related projects in a group and create a group access token under https://git.example.com/groups/transmogrify/-/settings/access_tokens. Create the access token with a name of deploy-user@deploy-host, role Reporter and Scope read_registry.
Caveat 1: docker can only manage one set of login credentials per registry host. Either use non-privileged/user-space docker daemons separated by project (e.g. with different users on the deploy host, each one only managing one project), which is a topic of a different blog post. Or use a “Personal” Access Token for a global technical user which has access to all the necessary projects instead. (There’s a third option: Create multiple .docker/config.json files and set the DOCKER_CONFIG environment variable accordingly. This violates the “docker compose up should just work” requirement.)
Caveat 2: docker really doesn’t want to store login credentials at all. There’s a couple of layers of stupidity here. Just do the following (note: this will overwrite all previously saved docker logins on this host, but you shouldn’t have any):
Then you can do a normal login with the deploy token and it’ll work:
docker login registry.example.com
First deployment / Setup
Clone the repository and configure any overrides necessary. Then start the application.
git clone ssh://git@git.example.com/transmogrify/frobnicator.git
cd frobnicator
vi compose.override.yaml # Or whatever is necessary
docker compose up -d
Your project should now be running. Finish any remaining steps (set up reverse proxy etc.) and debug whatever mistakes you made.
Set up for autodeploy
On deploy-host (or a developer laptop) generate another SSH key. We’re not going to keep it for very long, so do it like this:
ssh-keygen -t ed25519 -f pull-key # Hit enter a couple of times for no passphrase
Also retrieve the SSH host keys from deploy host (possibly through another way):
ssh-keyscan deploy-host
On deploy-host, add the following line to ~deploy-user/.ssh/authorized_keys (where ssh-ed25519 AAA... is the contents of pull-key.pub from step 1):
In gitlab, on group level, configure variables (https://git.example.com/groups/transmogrify/-/settings/ci_cd):
Name
Value
Settings
SSH_AUTH
-----BEGIN OPENSSH PRIVATE ... (contents of pull-key from step 1)
File, Protected
SSH_KNOWN_HOSTS
results of step 2
SSH_DEPLOY_TARGET
ssh://deploy-user@deploy-host
You may use the environments feature of gitlab here, which will generally mean a different set of values per environment (and then choosing the environment in the job in the next step). Afterwards, delete the temporary files pull-key and pull-key.pub from step 1.
In your project’s or projects’ .gitlab-ci.yaml file (this is in the code projects, not necessarily the project containing compose.yaml), add this (the publish docker job is outside of the scope of this post):
Voila. Every time after a docker image has been built, a gitlab runner will now trigger a docker compose pull/up, with minimal security impact since that’s the only thing it can do.
Addenda
The preliminaries and initial setup can be automated with Ansible.
You can put the gitlab-ci configuration into a common template file that can be referenced from all projects. For example, we have a common tools/ci repository, so the only thing necessary to get auto deployment is to put
into a project and do the deploy-host setup and variable definitions (well, and add the other include files that handle the actual docker image building).